|
|

|
Новости
Статьи
Магазин
Драйвера
Контакты
RSS канал новостей
Программаторы 25 SPI FLASH
Адаптеры Optibay HDD Caddy
Драйвера nVidia GeForce
Драйвера AMD Radeon HD
Игры на DVD
Сравнение видеокарт
Сравнение процессоров
 В конце марта компания ASRock анонсировала фирменную линейку графических ускорителей Phantom Gaming. ...  Компания Huawei продолжает заниматься расширением фирменной линейки смартфонов Y Series. Очередное ...  Компания Antec в своем очередном пресс-релизе анонсировала поставки фирменной серии блоков питания ...  Компания Thermalright отчиталась о готовности нового высокопроизводительного процессорного кулера ...  Компания Biostar сообщает в официальном пресс-релизе о готовности флагманской материнской платы ... |
АРХИВ СТАТЕЙ ЖУРНАЛА «МОЙ КОМПЬЮТЕР» ЗА 2002 ГОДЯ твой слуга, я твой работник
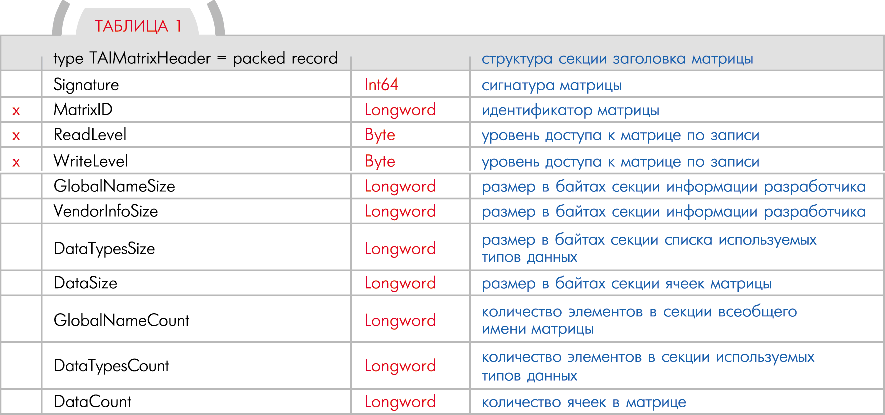
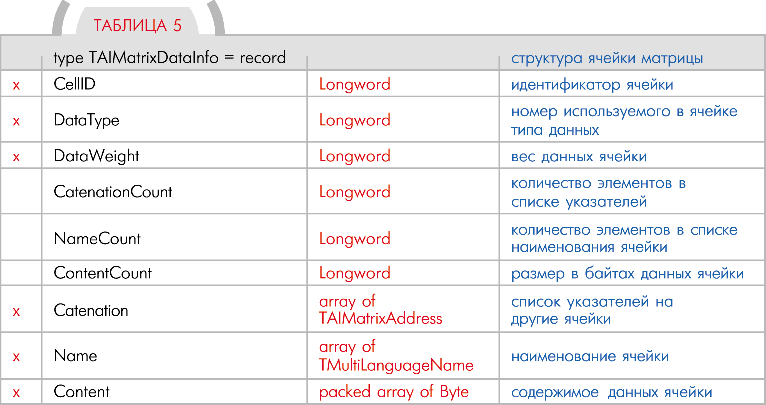
Дмитрий САХАНЬ. AIMatrix_Creator@chat.ru (Продолжение, начало см. в МК № 6—7 (177—178)) Секция заголовка матрицы Секция заголовка содержит всю основную информацию для транспортировки матриц Поле MatrixID содержит уникальный идентификатор матрицы (ее номер). Чтобы обратиться к определенной ячейке какой-либо матрицы, необходимо указать идентификатор желаемой матрицы, а за ним идентификатор требуемой ячейки. Левая часть указателя на ячейку всегда будет содержать номер матрицы, а правая часть — номер ячейки. Например, указатель 43:25 указывает на 25-ю ячейку 43-й матрицы. Поля ReadLevel и WriteLevel предназначены для задания уровня доступа по чтению и по записи к данной матрице. Чем больше значение в этих полях, тем выше должен быть уровень у инициатора запроса для доступа к данным матрицы. На практике эти поля могут вообще не использоваться, либо использоваться совершенно для других целей. Но при помощи них можно реализовать следующую схожую с человеческой особенность поведения робота. Пример для поля ReadLevel. Роботу задают вопрос: Ты любишь Аню? А матрица с данными об Ане помечена как «очень личное» для робота (то есть, имеет самый высокий уровень доступа). Инициа тор запроса данных об Ане — в нашем случае это будет система построения ответа на вопрос — имеет низкий уровень доступа, чтобы оперировать самыми «сокровенными» чувствами робота. Но программный движок робота обязательно должен возвратить инициатору запроса какой-то результат, которым могут быть заранее занесенные в матрицу фиктивные данные для «не вхожих в круг секретности» инициаторов. Вот вам один из простых вариантов реализации лжи. Пример для поля WriteLevel. Если для робота предусмотреть возможность порождать себе подобных, плюс возможность изменять какие-нибудь признаки наследственности, то неизбежно придется решать вопрос, каким образом робот будет менять эту наследственность. Ведь матрица ДНК робота в этом случае должна иметь максимальный уровень доступа по записи. А система изменения наследственных признаков робота должна располагать очень вескими основаниями (соответствующий уровень доступа), чтобы производить операции записи в матрице ДНК. Секция всеобщего имени матрицы Эта секция поддерживает многоязычность и предназначена для вполне обычной текстовой метки матрицы. Несмотря на то, что к матрице необходимо обращаться через ее идентификатор и номер ячейки, вам может понадобиться эта секция для каких-то нестандартных действий. Во-первых, при разработке логики робота очень удобно сопоставлять каждому идентификатору матрицы какое-нибудь общеупотребительное человеческое слово (имя). Во-вторых, появляется возможность реализовать в программном движке механизм обработки запросов с заведомо неизвестным идентификатором матрицы, но известным именем. Например, роботу задают вопрос: Ты знаешь Петю?. Очевидно, проанализировав секции всеобщих имен матриц, он сможет найти идентификаторы матриц, относящихся ко всем известным роботу Петям. Как можно заметить, секция всеобщего имени представлена в структуре матрицы массивом из элементов с типом TMiltiLanguageName, что позволяет реализовать многоязычность. Поэтому здесь мы рассмотрим именно этот тип. Он позволяет задать имя на каком-нибудь конкретном языке мира. Идентификатор языка задается так, как он задается для Wide-строк в Windows. Например, код русского языка он равен 0419h, код украинского —0422h, английского —0409h, немецкого —0407h, французского —040Bh и так далее. Обратите внимание, что количество элементов в секции всеобщего имени задается полем Поле Name содержит всеобщее имя матрицы, по которому ее необходимо искать, пользуясь различными строковыми функциями поиска. Поле Description позволяет указать рядом с именем матрицы какой-нибудь дополнительный комментарий к ней, к ее содержанию или назначению. Секция информации разработчика Данная секция содержит информацию, относящуюся к разработке соответствующей матрицы. Поскольку разработчиками могут продаваться даже отдельные матрицы, то эта секция предназначается для заполнения данных о версии матрицы, Все поля секции должны заполняться группой разработки логической части, но они никак не используются в самой логике робота. Думаю, что с назначением каждого из этих полей вы разберетесь и без моей помощи. Секция используемых в матрице типов данных Это вспомогательная секция, она не имеет влияния на логику робота. Ее назначение — хранить во время разработки матрицы список используемых в ней типов данных. В дальнейшем группа «логиков» решает, стоит ли удалить этот список из матрицы. Таким образом, данная секция может вообще отсутствовать. Она представлена массивом из элементов с типом TAIMatrixDataType. Количество элементов в секции задается полем DataTypesCount секции заголовка матрицы (табл. 4). Секция может не отражать полный список используемых в матрице типов данных, но я думаю, что в нее стоит вносить все используемые типы. Тем более, что это позволит избежать проблем при стыковке разных матриц от разных Вот пример некого небольшого списка использованных типов данных. 1. Нечеткая истина 3. Text 4. Целое число 32. Bitmap image 64. Обработчик правой руки 2048. Видеофрагмент Как видно из списка, он несет чисто информативную функцию и не претендует на полноту и достоверность. Этим списком разработчик как бы заявляет своим коллегам и будущим сотрудникам, что он использовал такие-то и такие-то типы данных, тем самым помогая им быстрее разобраться в подключении матрицы. Секция ячеек матрицы Секция ячеек также представлена массивом из элементов с типом TAIMatrixDataInfo. Собственно говоря, она и содержит всю логику матрицы. Количество элементов в секции задается полем DataCount секции заголовка матрицы. Каждый конкретный элемент секции является отдельной ячейкой матрицы (табл. 5). Поле CellID содержит уникальный идентификатор ячейки. Что значит этот идентификатор, было описано выше в поле идентификатора матрицы. В ячейку помещаются какие-нибудь данные, а значит, они имеют какой-то тип. В поле DataType заносится номер помещенного в ячейку типа данных. Как было сказано ранее, частичный или полный список наименований используемых типов находится во вспомогательной секции DataTypes (см. структуру матрицы). Поле DataWeight предназначено для задания какого-нибудь числового параметра данных в соответствующей ячейке по отношению к чему-то определенному. Поле Catenation содержит список различных указателей на другие ячейки в матрицах (не только на ячейки текущей матрицы). Собственно, поле представлено массивом из элементов TAIMatrixAddress. Этот тип будет рассмотрен чуть ниже. Количество элементов в массиве задано полем CatenationCount этой же структуры. Несмотря на то, что все указатели имеют одинаковую структуру, вариации их видов и способов использования зависят только от возможностей программного движка вашего робота. Поле Name предназначено для хранения имени конкретной ячейки. По своей структуре это поле схоже с полем всеобщего имени матрицы. Оно так же поддерживает многоязычность и тоже является массивом из элементов с типом TMultiLanguageName, но количество элементов в этом массиве задается полем NameCount структуры ячейки матрицы. Опять же, поле имени ячейки может использоваться для разных целей. Вам никто не мешает реализовать функции поиска по наименованиям ячеек. Тогда, например, на вопрос: «Что такое вилка?», робот сможет найти все адреса ячеек, которые содержат данные о вилках. Поле Content представлено массивом из байт и содержит в себе помещенные в ячейку данные. Размер массива задан полем ContentCount этой же структуры. Массив просто содержит данные, а их структура определяется уже вашими собственными законами, разработанными вами же для этого типа данных. Например, нужно поместить классический текст: «Здравствуй, мир!» в ячейку. Это у нас будет тип данных — строка. Дадим этому типу, например, номер 18. Значит, в поле DataType заносим число 18, в поле ContentCount заносим число 16 (длина строки), а в массив поля Content заносим один за другим все символы строки. Или такой пример. Допустим, мне нужно использовать в ячейке свою структуру данных с двумя полями: одно из 7 байт (а не из 4-х, как обычно) для целого числа, а другое из 3 байт для какого-то признака. Даю этому типу данных свой номер. Представим, что у меня уже используется 18 разных типов данных. И новому, чтобы не нарушать нумерации, я решаю дать номер 19. Этот номер заношу в поле DataType. В поле ContentCount заношу число 10 (размер данных = 7 байт для первого поля плюс 3 байта для второго). Ну, и в массиве поля Content выделяю место для 10 байт моей собственной структуры данных. При необходимости заношу какие-то изначальные значения в поля этой структуры. Таким образом, в ячейке оказалась записана новая структура, а ее обработка уже входит в задачи программного движка робота. Ведь «логику» неинтересно, как извлекается, сохраняется или обрабатывается определенный тип данных. Для него поле Content является источником данных, а как они там хранятся — это не его вопрос, а программистов. Теперь рассмотрим тип TAIMatrixAddress, с помощью которого задается указатель на другую ячейку ( Поля MatrixID и CellID содержат указатель на определенную ячейку. Как было сказано выше, адрес ячейки задается идентификатором ее матрицы плюс идентификатором самой ячейки. Поле Relation предназначено для задания типа соответствующего указателя. Кроме того, это поле можно использовать, например, для задания уровня весомости данного указателя по отношению к другим указателям в списке. То есть, возможности для использования поля очень широкие. В зависимости от его значения это может быть указатель перехода, указатель вызова какой-нибудь функции обработки периферийных устройств робота, указатель соответствия ячейки какой-то другой ячейке, указатель уровня важности обработки некой ячейки и так далее. Знакомьтесь — основные типы данных. Как уже было заявлено ранее, моя идея позволяет использовать любые типы данных. Не мне вас, учить какой из них и как использовать. Но все же я подробнее остановлюсь на одном типе, в основе своей заимствованном мной из нечеткой логики. Тип FuzzyTrue —нечеткая истина — основной элемент для создания нечеткой логики. Если в булевой логике есть два значения (истина и ложь), то в нечеткой логике между истиной и ложью лежит много значений. Эти значения можно назвать долями вероятности результата. В обычном языке человек выражает доли вероятности при помощи наречий («чуть», «слегка», «менее», «более», «почти», «около», «где-то рядом», «совсем близко» и т. п.). А значит, на любой нечеткий смысл мы можем найти какой-то четкий диапазон понятий. Рассмотрим пример. К вам обращаются: «Дай мне немного семечек». Несмотря на то, что «немного» — понятие растяжимое, вы отдадите действительно немного, а не все семечки. Немного — это всего лишь доля вероятности от всех имеющихся у вас семечек. И эта доля при всей своей кажущейся нечеткости имеет достаточно четкие математические грани. Причем, вспомните, каждое последующее отдаваемое «немного» начинает уменьшаться пропорционально оставшемуся количеству семечек. И каждое «немного» будет всегда приблизительно столько-то процентов от имеющихся семечек. Теперь, если мы определенным словам сопоставим конкретные процентные отношения, то их смысл уже не будет казаться таким расплывчатым (процентные отношения взяты «с потолка», исключительно для наглядности). Также обратите внимание на тот факт, что каждому нечеткому вопросу всегда явно или неявно ставится в ограничение соответствующий диапазон ответов. То есть, «дайте мне чуточку соли» от ее объема на столе, а не где-нибудь в вагоне на складе. Таким образом, при помощи типа FuzzyTrue можно дать четкий числовой ответ на нечеткий вопрос с конкретным диапазоном ответов. Не обязательно привязывать ответ к процентам. Это может быть, например, и 200 единиц от общего количества в 38000 единиц (немного сахара от его объема в мешке). Как в булевой логике выполняются разные операции над булевыми типами, так и в нечеткой логике над типом FuzzyTrue можно выполнять операции AND, OR, XOR и т. п. Но результатом будет уже нечеткое множество, потому что операция выполняется не над одними долями вероятностей, а над долями, привязанными к их диапазонам результатов. Соответственно, полученное множество будет читаться приблизительно так: с такого по такой диапазон доля вероятности такая-то, от сих и до сих — сякая, в этом диапазоне — еще какая-нибудь и т. д. Значит, нечеткое множество можно представить массивом значений, где каждый первый элемент значения задает диапазон или какую-то определенную его точку, а второй элемент задает долю вероятности для этого диапазона или точки. Чтобы вы не запутались, объясню это на следующем примере. Представим, что в одном магазине решили создать робота, раздающего рекламные буклеты входящим в магазин покупателям. Но раздавать нужно не всем подряд, а только определенному кругу людей. Считаем, что в магазине решили выбирать покупателей по возрастному признаку (а ведь робота можно научить выбирать и по дороговизне одежды, количеству золотых украшений, классу подъехавшей машины и т. д.). Нам пока не важно, как в магазине научили робота определять, стар или молод покупатель. Мы смотрим, как он использует нечеткое множество. Для простоты считаем, что он раздает один вид буклетов, подходящий для всех желаемых возрастных категорий. Если буклеты для каждой категории разные, то работа будет вестись с несколькими нечеткими множествами, а не с одним. Итак, к примеру, робот получает от руководства магазина 1000 буклетов и несколько указаний по возрастным категориям: Безусловно, малое количество параметров можно не объединять в множество и обрабатывать их скачками по разным ячейкам матрицы, где эти параметры сохранены. Но что если указаний становится все больше и больше? Все же лучше объединить их в множество и хранить в одной ячейке матрицы. В результате робот применяет операцию OR (логическое сложение) ко всем полученным указаниям и выводит из них нечеткое множество. Здесь я тоже процентные отношения взял «с потолка». Элементы нечеткого множества я упорядочил по первому полю элементов — диапазону возрастов. Второе поле — это процент выдаваемых от оставшихся у робота буклетов соответствующей возрастной категории покупателей. После операции OR 16-летний возраст попал в диапазон с большей долей вероятности. Заметьте, что в 40-летний возраст я поставил слово «каждому». На самом деле, вместо этого слова реально используется некое число, которое указывает программному движку робота, что это не процент от возрастной категории: Далее робот оценивает возраст входящего покупателя, сравнивает возраст с нечетким множеством и поступает в зависимости от результата, извлеченного из нечеткого множества. (Продолжение следует) Рекомендуем ещё прочитать:
|
|
|
 Идёт загрузка...
Идёт загрузка...| Хостинг на серверах в Украине, США и Германии. | © sector.biz.ua 2006-2015 design by Vadim Popov |