|
|

|
Новости
Статьи
Магазин
Драйвера
Контакты
RSS канал новостей
Программаторы 25 SPI FLASH
Адаптеры Optibay HDD Caddy
Драйвера nVidia GeForce
Драйвера AMD Radeon HD
Игры на DVD
Сравнение видеокарт
Сравнение процессоров
 В конце марта компания ASRock анонсировала фирменную линейку графических ускорителей Phantom Gaming. ...  Компания Huawei продолжает заниматься расширением фирменной линейки смартфонов Y Series. Очередное ...  Компания Antec в своем очередном пресс-релизе анонсировала поставки фирменной серии блоков питания ...  Компания Thermalright отчиталась о готовности нового высокопроизводительного процессорного кулера ...  Компания Biostar сообщает в официальном пресс-релизе о готовности флагманской материнской платы ... |
АРХИВ СТАТЕЙ ЖУРНАЛА «МОЙ КОМПЬЮТЕР» ЗА 2003 ГОДЯзык, на котором говорят везде
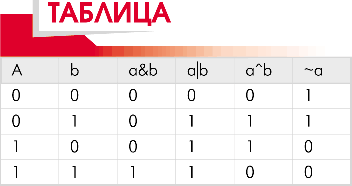
(Продолжение, начало см. в МК № 1-2 (224-225)). Кстати, в прошлый раз я забыл вам сказать, что слова signed и unsigned можно использовать без собственно имени типа. Тогда после них подразумевается int. Еще одна вещь по поводу типов, которую стоит рассказать сразу. Это автоматическое (или неявное) приведение типов. Эти три мутных слова означают, что вы можете любые переменные любых простых типов переназначать друг другу. К примеру, если вы возьмете нечто типа int и присвоите его другому нечту типа long, то оно просто дополнится сверху нулями. Вообще, если вы будете присваивать любой простой тип более широкому типу, то значение передастся без изменений. С присвоением «в обратную сторону», конечно, все не так безоблачно. Более широкий тип при передаче значения более узкому, естественно, не может остаться неизменным (не поместится просто). Например, float при передаче int’у потеряет свою дробную часть, а int при переводе в char лишится старшего байта (или нескольких, смотря насколько был большой). За это, кстати, приведения типов «в меньшую сторону» иногда в шутку называют «привидениями типов». Некоторые считают «хорошим тоном» всегда и везде приводить типы явно, но по-настоящему это может быть надо разве что вам самим, чтоб не заблудиться в своей программе (если вы не помните, чего у вас какого типа), а компилятору это до фени. На мой взгляд читабельность программы от этого скорее теряет; если не можете запомнить типы своих переменных, лучше давайте им соответственные буквенные префиксы. Имя, сестра, имя! Естественно, сами типы не очень-то кому-то нужны без возможности объявлять переменные и функции этих типов. Итак, какие могут быть имена переменных и функций (имярек «идентификаторы»)? Тут все стандартно: допустимое имя — это последовательность букв, цифр и подчерков (‘_’), начинающаяся не с цифры. Надо отметить, что прописные и строчные (то есть большие и махонькие) буквицы в именах различаются. То бишь myname, MyName и MYNAME — разные имена. Кстати сказать, в простых сях приняты имена токмо из маленьких буковок (слова при этом разделяются подчерками, вот так: my_name), а заглавные оставлены для дефиниций (есть такая директива define, потом расскажу), а в плюсах (да и вообще в ООП) принят второй из приведенных вариантов (каждое слово — с большой буквы; наверное, америкосы придумали, они так любят). Хотя на самом деле это, конечно, дело вкуса. Еще насчет длины имен. В ранних компиляторах эта длина ограничена тридцать одним символом. В некоторых современных компиляторах вроде бы ограничитель поднят до 255 символов (не знаю, не проверял). Если это даже и правда, все равно не знаю, нафиг кому надо такие именищи выдумывать, 31 — и так выше крыши. Ограничение это, впрочем, не означает, что компилятор начнет материться, когда увидит непомерно длинное имя, просто все символы после 31-го (соответственно, 255-го) будут проигнорированы. В смысле, если вдруг у вас хватит терпения подсунуть компилятору два имени, разница между которыми начинается после 31-го символа, то он их примет за одно и то же. Не могу не рассказать об одном курьезе: исходя из этого определения простой подчерк — тоже полноценное имя; и действительно, в сях переменная или функция запросто может называться ‘_’ (‘__’, ‘_1’ и т. д.). В общем-то, не более чем занимательная мелочь, но я привык называть так временные, не важные для смысла переменные — читабельность программы от этого несколько повышается (сразу знаешь: то, что без буковок — эт так, фигня). С типами и именами разобрались, перейдем к третьей важной составляющей языка. Операция «Ы». Операции — это, конечно, и есть эта третья составляющая. О них я сначала расскажу в логическом порядке, а потом перечислю в порядке приоритетов. Хотя многие из этих приоритетов вы, возможно, почти сразу благополучно забудете (обычно так бывает). Ну да ладно, поехали по порядку. Сразу оговорюсь: стандартная операция бинарна, то бишь с двумя аргументами — один справа, другой, соответственно, слева. Кроме бинарных существует несколько унарных операций (у них единственный аргумент пишется справа), а одна даже тернарная (с тремя аргументами; очень, кстати, интересная штука). 1. Арифметика (+, –, *, /, %) Ну, со сложением, вычитанием и умножением все просто, как угол дома — это вы все в школе учили. С делением есть нюансы. Дело в том, что целочисленное деление — это то же самое, что и обычное деление. «Как это?» — спросите вы. А очень просто. Ведь целочисленное деление — это просто-напросто деление с последующим отбросом дробной части. А помните, что я там писал про автоприведение типов? Вот именно. Если результат обычного деления передать в целочисленную переменную — мы получим то самое целочисленное деление. Только надо тип соответственный подобрать, чтобы результат в ем поместился. Ну вот, с делением теперь тоже все ясно. Остался еще какой-то непонятный процент. Им означается остаток от деления. Уж не знаю, какая тут у Ричи логика сработала; может, что черточка в проценте на знак деления похожа (я, по крайней мере, именно так это сразу запомнил). Есть еще унарные версии плюса и минуса. Минус — понятно: это для отрицательных чисел. Кому и для чего может пригодиться унарный плюс, я никак не могу придумать, но все-таки он зачем-то существует. 2. Инкремент, декремент (++, -- (унарные)) Эти штуки просто прибавляют и отнимают единичку. Некоторые считают, что это сделано для удобства организации счетчиков. А мне кажется, соль не в этом; дело в том, что инкременты-декременты для проца (по крайней мере, интел-совместимого) — принципиально другие команды, нежели сложение-вычитание; они, во-первых, занимают в машкоде (машинном коде) меньше байтиков, а во-вторых, выполняются быстрее. Так что тут явно налицо оптимизация (хоть и маленькая, но хорошая: когда инкремент/декремент применяется в тех же счетчиках циклов, например, то при прокрутке цикла много тысяч раз разница может стать видна невооруженным глазом). А эти операции есть, кстати, и в других языках, например в паскале, но там ими далеко не все пользуются (может, потому, что организовано не так красиво). Инкре-декре-менты еще интересны тем, что они, единственные из унарных операций, могут писаться и перед, и после аргумента (т.н. «префиксная» и «постфиксная» форма). Если написать плюсики/минусики спереди, то значение увеличивается/уменьшается до подстановки в выражение, а если сзади — то после. Поясню на примере. Пусть у нас x равен, к примеру, трем. Если вы напишете a=x++, то сначала выполнится a=x, а уже потом x++. Таким образом x станет равен четырем, a — трем. Если же написать a=++x, то сначала выполнится инкремент, а потом уже присвоение, то есть a уже будет равняться четырем. Еще тут вроде бы есть какая-то неопределенность с приоритетами этих -ментов и арифметики. Многие учебники пишут, что если вы напишете, например, x+++y, то одни компиляторы могут это понять как (x++)+y, а другие — как x+(++y). Кто эти «одни», а кто — «другие», все книжки молчат, как партизаны, но на всякий случай рекомендуют все везде обскобивать. Как работают такого плана заковыки без скобок, я на практике не проверял, ибо даже если знать, как тот или иной отдельно взятый компилятор их поймет, то все равно с точки зрения читабельности это выглядит убийственно. А дабы не нагромождать, я в таких случаях использую пробелы (например, x++ +y вместо (x++)+y).*** 3. Булевы операции (&, |, ^, ~ (унарная)) Некоторые называют их еще «побитовые» или «поразрядные», подчеркивая этим, что они оперируют с отдельными битиками (двоичными разрядами). & — это побитное «и», каждый бит результата равен 1, только если оба соответствующих бита аргументов единичные. | — побитное «или», ему достаточно хотя бы одной единицы, чтобы и в результате была единица. ^ — «исключающее или» (то, которое во всяких там бейсиках и еще где ни попадя пишется как xor, за что его еще иногда в шутку называют «икслючающее или»), ему нравится, когда биты аргументов разные — тогда он ставит на этом месте 1, если одинаковые — то 0. ~ — «нет», он все отрицает, говоришь ему «0» — он 4. Сдвиги (<<, >>) Это тоже побитные операции. Они «сдвигают» двоичную форму целого числа на заданное число битиков в ту (<<) или иную (>>) сторону, дополняя с другой стороны нулями. К примеру, если x равен 5, что в двоичной форме представится как 101, то x<<2 вернет 10100, что в десятичном виде есть 20, а x>>1 вернет 10, что есть 2. Вообще, как нетрудно догадаться, << равносильно умножению на указанную справа степень двойки, а >> — целочисленному делению на нее же. 5. Присвоения (=, +=, -=, *=, /=, %=, &=, |=, ^=, <<=, >>=) С обычным знаком равенства все понятно: он считает то, что справа и отдает тому, что слева. А вот что это за +=, –= и т.д., новичку в Си так просто не понять. В книжках, кстати, чтобы сразу еще больше запутать народ, эти штуки называют страшными словами «присваивание со сложением», «присваивание с вычитанием» и т.п. (особенно хорошо звучит «присваивание с поразрядным исключающим или»). А операции эти просто берут то, что справа, и прибавляют (вычитают, умножают и т.д.) тому, что слева. То есть, вместо того чтобы писать x=x+y, мы пишем x+=y. На самом деле в этом опять-таки кроется не просто сокращенная запись, как многие думают, но еще и оптимизация. Каждая переменная или выражение при выполнении программы хранится в каком-то участке (который мы условно называем «ячейкой») памяти. Простое присвоение (x=x+y) сначала резервирует новую временную ячейку (это делается, чтобы не затереть значение икса, которое используется при вычислении того, что справа), равную по размеру переменной, стоящей в левой части, затем копирует туда первое слагаемое, затем прибавляет туда же второе, и потом уже копирует результат в ячейку икса и освобождает временную ячейку. Второй же вариант (x+=y) просто прибавляет значение игрека в ячейку икса. Как видите, это экономит и время, и чуть-чуть памяти. 6. Сравнения (<, >, <=, >=, ==, !=) Сравнения возвращают 1, если выполняется соответствующее условие между левым и правым аргументами, а если условие не выполняется — возвращают 0. Условия такие: < — «меньше», > — «больше», <= — «меньше или равно», >= — «больше или равно», == — «равно», != — «не равно». Заметьте, что значения у сравнений — числовые. Таких понятий, как true, false, в сях нету. В некоторых вариациях плюсов появились, правда, какие-то true и false, но на поверку они оказались просто глобальными переменными с соответственными значениями, объявленными где-то в основных библиотеках. Так что на самом деле и в обычных сях, и в плюсах можно использовать результаты сравнений как числа. Тут, правда, есть одно «но». Некоторые компиляторы в качестве правды используют не 1, а -1. В одной особо одаренной книжке я прочитал, что якобы это делается потому, что в «минус единице» (в ее машинном виде) установлены в 1 все биты, а в «плюс единице» — только младший. То бишь, смысл вроде бы в том, чтобы сделать максимум разницы между правдой и ложью (как будто иначе проц эту разницу случайно растеряет по дороге). Причем, там безапелляционно заявлялось, что правда равна -1 во всех языках высокого уровня. В общем, смысл «отрицательной правды» для меня остался загадкой. А мораль сей басни такова: прежде чем использовать правду как число, проверьте, какое это будет число в интертрепации вашего компилятора. Но вернемся к сравнениям. С первыми двумя все просто. О вторых двух стоит сказать только одно. В некоторых языках допустимы оба их возможных написания: как <=, так и =<. Но не в сях. Тут работает только первый вариант. Потому что просто непонятно, зачем нужны две конструкции для одной и той же операции. А привыкнуть легко: вы же не скажете словами «равно или меньше», а скажете «меньше или равно» — так и значками пишите только в такой последовательности. Два знака равенства — это не опечатка. Просто надо же как-то отличать сравнение от простого присвоения. В Паскале (не удивляйтесь, что я все время провожу сравнения только с Паскалем — он был создан почти сразу после Си и изначально считался самым близким к нему языком по построению) решили почему-то сравнение писать как =, а присвоение — как :=. Сишный же вариант заметно удобнее: представьте, во сколько раз в среднестатистической программе присвоений больше, чем проверок равенства. Мой первый опыт на Паскале заключался в том, что я за полчаса набросал не очень сложную программку, а потом 20 минут методично вставлял двоеточия перед каждым знаком равенства (была когда-то такая машина, Yamaha MSX-2 — в тамошней паскалевской среде поиска-замены, увы, не было). С тех пор я с Паскалем не дружу. А почему так странно пишется знак «не равно», вы сейчас поймете. 7. Логические операции (&&, ||, ! (унарная)) && — это логическое «и», || — «или», ! — «нет» (теперь понятнее, почему «не равно» пишется через восклицательный знак?) Эти операции работают с аргументами в точности так же, как булевы — с отдельными битиками, но все, что не 0, принимают за 1. То есть, && возвращает 1, только если оба аргумента не нулевые (если хотя бы один нулевой, то 0), || возвращает 0, только если оба нулевые (иначе — 1). ! возвращает 1, если аргумент нулевой, и 0, если наоборот. Тут надо заметить, что && и || проверяют сначала первый аргумент и, если из его значения результат уже становится известен, то второй вообще не вычисляется. Например, если у && первый аргумент окажется нулем, то она сразу этот ноль вернет, не считая второго аргумента. Это дает возможность давать, например, вот такие конструкции: x!=0 && 2/x>3. Ошибки деления на ноль тут точно не будет, так как если икс будет равен нулю, то вторая часть условия будет просто отброшена. Кроме того, благодаря отбрасыванию ненужных условий еще и время лишнее на их вычисление не тратится. Еще за счет того, что логика в сях работает не с какими-то непонятными true и false, а с числами, некоторые условия можно вообще опускать (экономя, опять-таки, процессорное время на их выполнении). Так, приведенное для примера x!=0 && 2/x>3 можно записать как x && 2/x>3 — это будет то же самое. 8. Адресные операции (&, * (унарные)) Имеют отношение к указателям, так что когда перейдем к последним, тогда ими и займемся. 9. Операции выбора элемента (., ->) Эти операции относятся к составным типам (структурам, союзам, а в плюсах — еще и к классам) и предоставляют доступ к элементам, из которых эти составные типы состоят. Так что о них тоже позже. 10. Условная операция (?:) Да, в сях, помимо условной конструкции (if), есть еще и условная операция. Это, кстати, и есть та тернарная операция, о которой я говорил в начале. Штука несколько непривычная, но довольно удобная. Пишется она так: c?t:f. А работает так: сначала вычисляет c; если это правда (то есть, «не ноль»), то вычисляет t и возвращает результат; если неправда (ноль), вычисляет f и возвращает результат. Прошу заметить, что из t и f вычисляется только то выражение, которое надо вернуть. Для того чтобы объяснить, как это работает, переведу на язык ?: свой примерчик с UpCase’ом из предыдущей статьи (который мы теперь уже умеем написать так: if(x>=’a’ && x<=’z’) x+=’A’-’a’). Можно это написать так: x+=(x>=’a’ && x<=’z’ ? ’A’-’a’ : 0); что в переводе означает: к иксу прибавить выражение в скобках, где выражение в скобках равно ’A’-’a’, если x — маленькая буква, а иначе 0. Эти два варианта с точки зрения компилятора ничем не отличаются, и дал я их только для того, чтобы проиллюстрировать операцию ?:, а заодно показать, что Си — достаточно гибкий язык, который позволяет делать очень многие вещи и даже не одним способом. Вот и все сишные операции. Выясним теперь, кто из них главнее, то есть перейдем к приоритетам. Операции, входящие в одно выражение, выполняются в порядке убывания приоритетов. Наивысший приоритет имеют круглые скобки (), использующиеся для группировки, квадратные скобки [] (доступ к элементам массивов) и операции выбора . и ->. На второй ступеньке стоят все унарные операции: *, & (адресные), – (унарный минус), ! (логическое «нет»), ~ (булево «нет»), ++— (инкремент и декремент). Далее идут по убыванию: *, /, % (умножение и деления); +,–(сложение и вычитание); <<, >> (сдвиги); <, >, <=, >= (меньши-больши); ==, != (равно-неравно); & (булево «и»); ^ (булево «исключающее или»); | (булево «или»); && (логическое «и»); || (логическое «или»); ?: (условная операция). На последней ступеньке стоят толпой все присвоения: =, +=, -=, *=, /=, %=, &=, |=, ^=, <<=, >>=. Теперь мы с операциями уже совсем покончили, в следующий раз начнем рассматривать всяческие конструкции и операторы и по ходу дела начинать писать простенькие программки с их применением. Так что рекомендую до того времени обзавестись каким-нибудь компилятором. Для линуксоидов, конечно, лучший выбор — штатный gcc (GNU C compiler). Ну, а виндузистам я бы рекомендовал отыскать где-нибудь старенький ДОСовский «Борланд Турбо Си», или, за неимением такового, C++ того же Борланда. Досовские вариации Зортека и Ваткома говорят с небольшим акцентом, а Борланд — это для ДОСа классика. Всякими же виндовыми средами пользоваться вообще пока запрещено, ибо у винды в сях совсем какой-то свой диалект, в котором идеология несколько другая, чем в оригинале. В общем, теперь мы уже будем заниматься не только теорией, а начнем, так сказать, боевое крещение, так что готовьтесь. До следующего раза... (Продолжение следует) Рекомендуем ещё прочитать:
|
|
|
 Идёт загрузка...
Идёт загрузка...| Хостинг на серверах в Украине, США и Германии. | © sector.biz.ua 2006-2015 design by Vadim Popov |